Software Configuration Management mit CVS
Im Rahmen des 'Kram des Monats' Projektes komme ich nun endlich dazu, einen kurzen und groben Überblick über das Concurrent Versions System, kurz CVS zu geben. Die Zeichnungen sind übrigens aus dem Netz zusammengeklaut, ich hoffe ihr stört euch nicht daran.
1. RCS/CVS - Einleitung
Um euch den Sinn eines SCM-Tools näher zu bringen und damit auf das Thema CVS überleiten zu können, stellt euch folgendes Szenario vor. Ihr arbeitet mit zwei Kollegen an einem Softwareprojekt, etwa einem kleinen Instant Message Tool für ein privates Firmennetzwerk. Während ihr euch um die graphische Benutzeroberfläche kümmert, schreibt ein anderer am Netzwerk Code, und der dritte am Datenmodell und der Integration. Ihr habt euch an alle heiligen Softwareengineering Methoden gehalten und euch vorher die Struktur überlegt, sowie die Schnittstellen und Modularisierung des Quellcodes gut durchgedacht (was in den wenigsten Fällen vorkommt, aber ihr seid ja Musterprogrammierer). Als kleines Handicap sei jedoch gesagt, dass ihr drei lokal komplett voneinander getrennt seid, und euch nur per Mail und anderen Netzhilfmitteln verständigen könnt. Also programmiert ihr euren Teil des Projektes, und seid sogar sehr erfolgreich damit (auch wenn ihr als GUI-Bastler noch so ziemlich ohne Funktionalität auskommen müsst...). Nun meldet sich einer eurer Kollegen, er habe die erste releasefertige Version seines Netzwerkmoduls fertig, und lässt sie euch per Mail zukommen. In der gleichen Zeit ist beim Datenmodell ein Bug aufgetreten, der aber schnell gefixt ist, auch hier ist die neue Variante unterwegs. Ihr kopiert also die neuen Sourcefiles in euer Verzeichnis und kompiliert, während vom Netzwerkmenschen ein paar Bugfixes reinkommen, und wieder ein paar Module auszutauschen sind (um die Mails schön klein zu halten, wird nicht das ganze Projekt verschickt, sondern nur die betroffenen Sourcefiles). Der Datenmodellierer hat keine Probleme mit der aktuellesten Versoin, lediglich beim Netzwerkmenschen fehlt ein kleiner Button (den er leider noch nicht bekommen hat), und bei euch spuckt ein kleiner Teil des Netzwerkcodes unzählige Exceptions aus, weil ein kleiner Codeteil nicht upgedatet worden ist.
Nun, bei drei Personen lässt es sich vielleicht noch synchronisieren, nehmt aber einmal eine Firma mit 10 Personen, die an 17 Modulen zu je ~125 Sourcefiles eines J2E Projektes arbeitet. Um dieses Horrorszenario gleich aus den Köpfen zu entfernen: es gibt Abhilfe, sogar ziemlich gute. Mit SCM möchte man dem gemeinschaftlichen Arbeiten an einem Projekt Herr werden, und das CVS ist dabei das wohl verbreiteste (und meiner Meinung nach beste) System, das für diesen Zweck existiert.
Bevor man allerdings mit CVS beginnt, muss noch ein anderes System, nämlich das Revision Control System genannt werden. RCS ist eigentlicht nichts weiter als eine Sammlung von Unix Tools, die eben für genau diesen Zweck gedacht sind. Es wird dabei ein sogenanntes Repository auf einem für alle Projektbeteiligten zugänglichen Server angelegt, der sämtliche 'Revision Groups' beinhaltet, also im großen und ganzen die Projekte, an denen gearbeitet wird. RCS erlaubt nun das Updaten von einzelnen Dateien in diesem Repository, so, dass sämtliche Revisionen gespeichert sind und auch zum Abruf bestehen. Um das ganze effizient zu machen, greift RCS dabei auf das beliebte Unix-Kommando 'diff' zurück, welches die Änderungen zwischen Dateien anzeigt und notfalls auch rückberechnen kann.
Obwohl RCS schon als ziemlich gute Toolsammlung gilt, gab es dennoch einige Deffizite, vor allem bezüglich Authentifizerung und Locks/Unlocks der Daten. So war es zum Beispiel nicht möglich, dass jemand an einer Datei arbeitet, auf der eine Sperre sitzt, die womöglich schon lange out-of-date ist. Für derartige Probleme gab es nun die nächste, logische Weiterentwicklung, CVS. CVS kann man nun als Frontend zu RCS betrachten. Das ganze ist strukturierter und einfacher zu bedienen.
2. Checkin, Checkout - Das Repository
Die zentrale Anlaufsstelle ist das sogenannte CVS Repository, indem alle Module in sogenannten Projekten abgespeichert sind bzw. werden. Je nach Rechtevergabe ist nun möglich, Projekte aus dem Repository runterzuladen, bzw. ins Repository hochzuladen, oder auch nur Änderungen an gewissen Dateien in den Projekten durchzuführen. Wie man nun ein Repository einrichtet, bzw. wie die technischen Hintergründe dazu aussehen, möchte ich euch ersparen. Das ganze würde den Rahmen dieses Tutorials sprengen. In [5] dürfte allerdings alle Interessierten fündig werden. Gehen wir also davon aus, dass wir bereits über ein Repository verfügen, und dort schon unser Instant Message Tool bereits in den drei Projekten 'IMNet', 'IMGui' und 'IMModels' untergebracht worden ist. Melden wir uns also am Authentifikationsserver des Repositories mit unserer Erkennung an:
cvs -d :pserver:muad@cvs:/repos login
Ich logge mich also mit meiner Benutzerkennung 'muad' am Server 'cvs' beim Repository 'repos' (einem Verzeichnis auf 'cvs') ein, gebe mein Passwort ein und authentifiziere mich somit. Diesen Schritt muss man genau einmal machen, die Logindaten werden für den Benutzer in der Datei .cvspasswd im Home-Verzeichnis gespeichert (und in Windows.... auch... irgendwo...). Jetzt ist er bis zum logout - Kommando immer am Server eingeloggt, auch wenn der Rechner heruntergefahren wird.
Nachdem wir uns angemeldet haben, holen wir uns sämtliche Projekte aus dem Repository.
cvs checkout IMNet
cvs checkout IMGui
cvs checkout IMModels
Das ganze nennt sich 'checkout', die Projekte werden - in ihrer aktuellsten Version - lokal bei uns gespeichert. Wer sich die Verzeichnisstruktur eines derartigen Projektes anssieht, wird feststellen, dass jedes Verzeichnis einen Ordner CVS enthält, der die nötigen Einträge zum einchecken und auschecken aus dem Repository enthält. Wir ändern nun eine kleine Datei namens 'file.c', und fügen ein paar Zeilen Code hinzu. Mit
cvs commit -m "Comment" file.c
übertragen wir die Änderungen am Repository. Die Datei, die vorhin in Revision 1.1 war, wird nun vom CVS automatisch in 1.2 upgedatet. Wenn jemand sich das Projekt nun auscheckt, bekommt er die bereits geänderte Datei mit. Anstatt sich das Projekt allerdings immer komplett runterzuladen, gibt es den Befehl
cvs update .
Der in diesem Falle das Verzeichnis, in dem man sich gerade befindet, updatet. Man kann natürlich auch einzelne Dateien updaten. Unterschiede zwischen den Dateien lassen sich mit
cvs diff file.c
ansehen.
Um neue Projekte/Dateien hinzuzufügen, kann man das Kommando
cvs add new.c
benutzen. Nachdem die Datei im Repository ist, kann sie 'commit'ed werden. Mit dieser Ansammlung an Befehlen ist es eigentlich schon möglich, seine Projekte damit zu versionieren und zu synchronisieren. Sämtliche GUI-Tools, so auch das Plug-In von Eclipse, greifen auf diese Befehle zurück. Allerdings gibt es noch einige weitere, tolle Features.
3. Branches und Sticky Tags
Eine geniale Sache bei RCS/CVS ist die Verwendung von Branches. Angenommen, ihr habt euer IM Tool mit Java entwickelt, und dazu das IBM JDK 1.4 verwendet. Nun möchtet ihr aber auf Java 1.5 von Sun umsteigen, um in die Gunst der neuen Features zu kommen. Allerdings sollt ihr natürlich auch eine gewisse Abwärtskompatibilität waren, da nicht jeder die dazu nötige Runtime installiert hat. Mit einem Branch könnt ihr nun den gegenwärtigen Zustand eines Projektes quasi spiegeln bzw. aufteilen. Anstatt nur auf ein Projekt einzuchecken, habt ihr nun zwei, und bei jedem könnt ihr nun Projektänderungen durchführen. In der Praxis werden Branches vor allem zu Maintenance Zwecken verwendet. Unser J2E Framework wird gerade in Version 4 entwickelt, während die Kunden immer noch Version 3 verwenden und hier natürlich keine Bugs wollen.
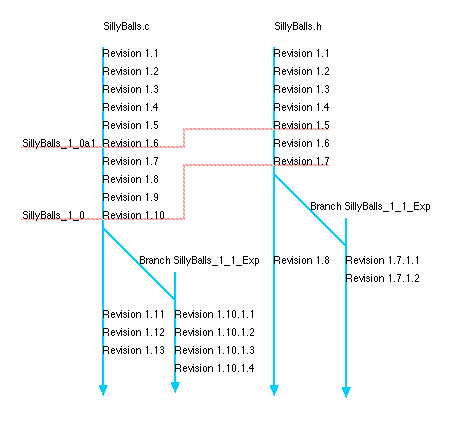
Der "Standard"-Branch nennt sich "HEAD". Dateien in Branches bekommen eine weitere Nummer in der Versionierung.
Für Firmen noch viel wichtiger ist die Verwendung von Sticky Tags. Mit einem Tag könnt ihr euer gegenwärtiges Projekt markieren. Da ihr natürlich nicht jede Datei immer updatet, kommt es unweigerlich dazu, dass sich die Versionsnummern der einzelnen Dateien gewaltig unterscheiden. Während das Interface im Headerfile immer noch Version 1.1 ist, kann eure Implementierung schon in Version 1.24 sein. Ein Tag ist nun quasi ein Index, der die Versionsnummern fixiert, die zu diesem Tag gehören. Das Bild veranschaulicht das vielleicht besser:

Wir verwenden Tags zum Beispiel, um Versionen unseres Frameworks zu markieren. So wissen wir, dass unser Kunde mit Version 3.23.112 diese und jene Java-Files besitzt, die allerdings in 3.23.113 schon wieder ganz anders aussehen bzw. sich anders verhalten.
Bei unserem private Projekt haben wir auch Sticky Tags verwendet, alleine um unseren Fortschritt zu fixieren und die lauffähigen Versionen zu kennzeichnen :)
4. Weiterführende Literatur
Fazit
Es gibt zwar noch einiges über CVS zu sagen, doch ich denke, einen grundlegender Überblick übermittelt zu haben. Als graphisches Frontend zu CVS wollte ich ursprünglich Eclipse noch vorstellen, doch ich denke, dass ist eventuell für ein weiteres Tutorial besser geeignet -- mit der Vielzahl an Plugins ist übrigens Eclipse durchaus auch für C Entwickler zu empfehlen, die immer noch nach einer guten CVS Unterstützung für ihre IDE suchen. Wenn ihr für eure Projekte CVS verwenden wollt, aber über keinen Server verfügt, und nichts dagegen habt, es als OpenSource freizugeben, werdet ihr bei SourceForge fündig.
Nun, ich hoffe, dass das ungefähr dem entspricht, dass ihr euch vorgestellt habt, und möchte mich nochmals für die große Verspätung entschuldigen. Fragen könnt ihr gerne in den Thread posten!





 Zitieren
Zitieren